
torchao: A PyTorch Native Library that Makes Models Faster and Smaller by Leveraging Low Bit Dtypes, Quantization and Sparsity
PyTorch has officially launched torchao, a comprehensive native library designed to optimize PyTorch models for better performance and efficiency. The launch of this library is a milestone in deep learning model optimization, providing users with an accessible toolkit that leverages advanced techniques such as low-bit types, quantization, and sparsity. The library is predominantly written in PyTorch code, ensuring ease of use and integration for developers working on inference and training workloads.
Key Features of torchao
Provides comprehensive support for various generative AI models, such as Llama 3 and diffusion models, ensuring compatibility and ease of use.
Demonstrates impressive performance gains, achieving up to 97% speedup and significant reductions in memory usage during model inference and training.

Offers versatile quantization techniques, including low-bit dtypes like int4 and float8, to optimize models for inference and training.
Supports dynamic activation quantization and sparsity for various dtypes, enhancing the flexibility of model optimization.
Features Quantization Aware Training (QAT) to minimize accuracy degradation that can occur with low-bit quantization.
It provides easy-to-use, low-precision computing and communication workflows for training that are compatible with PyTorch’s ‘nn.Linear’ layers.
Introduces experimental support for 8-bit and 4-bit optimizers, serving as a drop-in replacement for AdamW to optimize model training.
Seamlessly integrates with major open-source projects, such as HuggingFace transformers and diffusers, and serves as a reference implementation for accelerating models.
These key features establish torchao as a versatile and efficient deep-learning model optimization library.
Advanced Quantization Techniques
One of the standout features of torchao is its robust support for quantization. The library’s inference quantization algorithms work over arbitrary PyTorch models that contain ‘nn.Linear’ layers, providing weight-only and dynamic activation quantization for various dtypes and sparse layouts. Developers can select the most suitable quantization techniques using the top-level ‘quantize_’ API. This API includes options for memory-bound models, such as int4_weight_only and int8_weight_only, and compute-bound models. For compute-bound models, torchao can perform float8 quantization, providing additional flexibility for high-performance model optimization. Moreover, torchao’s quantization techniques are highly composable, enabling the combination of sparsity and quantization for enhanced performance.
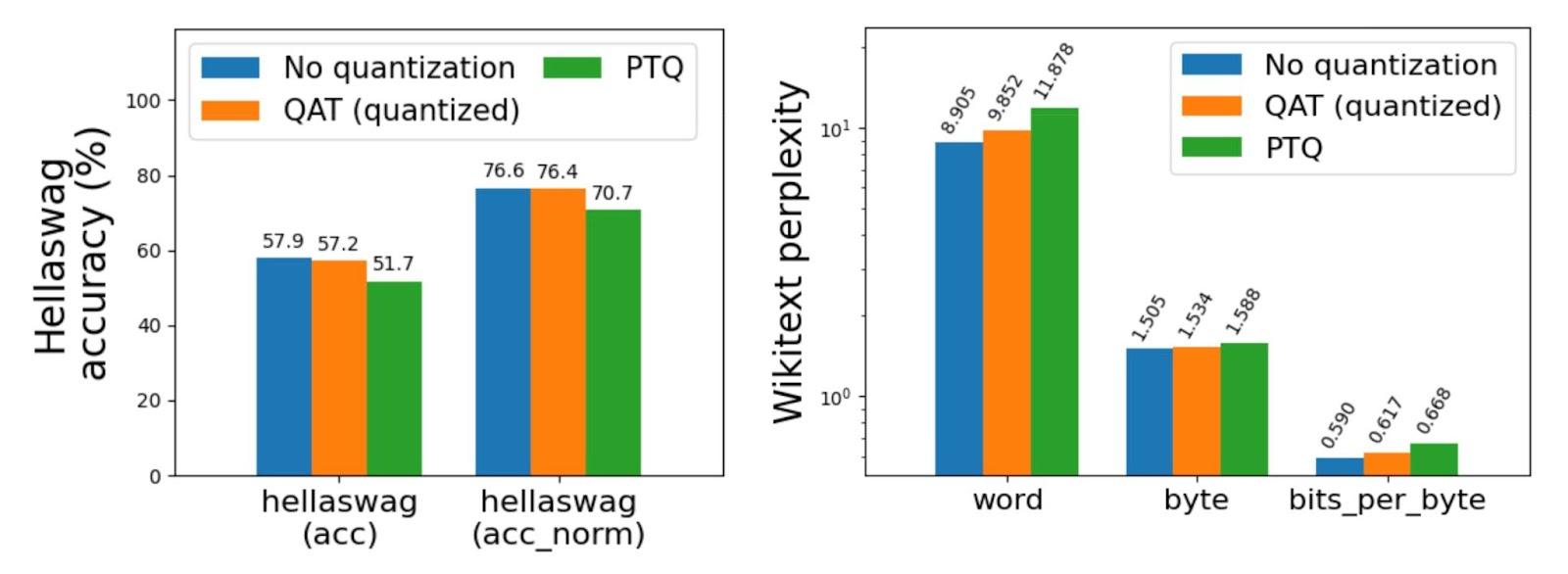
Quantization Aware Training (QAT)
Torchao addresses the potential accuracy degradation associated with post-training quantization, particularly for models quantized at less than 4 bits. The library includes support for Quantization Aware Training (QAT), which has been shown to recover up to 96% of the accuracy degradation on challenging benchmarks like Hellaswag. This feature is integrated as an end-to-end recipe in torchtune, with a minimal tutorial to facilitate its implementation. Incorporating QAT makes torchao a powerful tool for training models with low-bit quantization while maintaining accuracy.
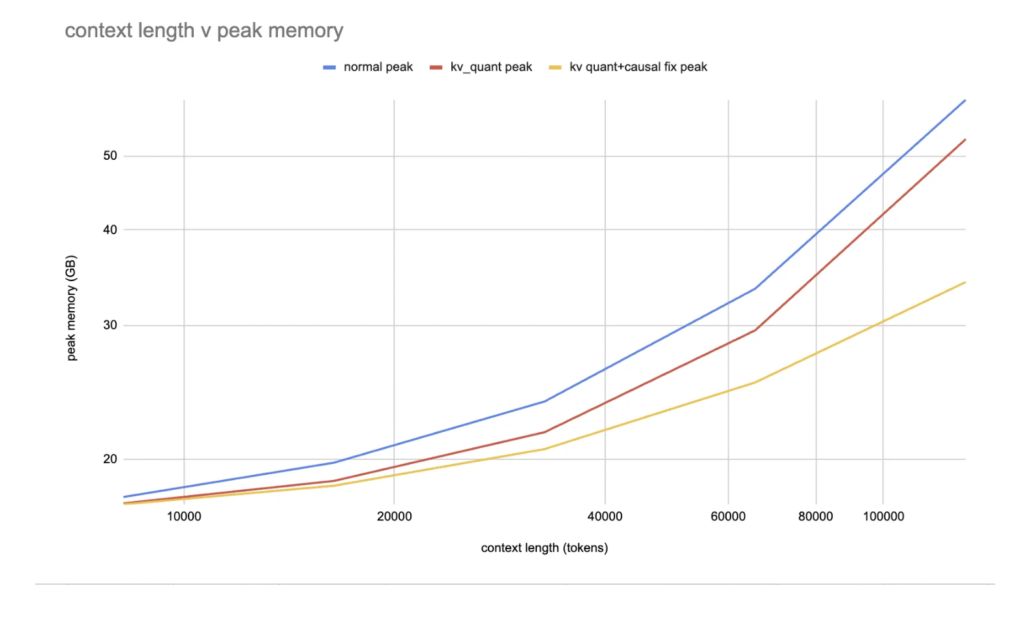
Training Optimization with Low Precision
In addition to inference optimization, torchao offers comprehensive support for low-precision computing and communication during training. The library includes easy-to-use workflows for reducing the precision of training compute and distributed communications, beginning with float8 for `torch.nn.Linear` layers.
Torchao has demonstrated impressive results, such as a 1.5x speedup for Llama 3 70B pretraining when using float8. The library also provides experimental support for other training optimizations, such as NF4 QLoRA in torchtune, prototype int8 training, and accelerated sparse 2:4 training. These features make torchao a compelling choice for users looking to accelerate training while minimizing memory usage.
Low-Bit Optimizers
Inspired by the pioneering work of Bits and Bytes in low-bit optimizers, torchao introduces prototype support for 8-bit and 4-bit optimizers as a drop-in replacement for the widely used AdamW optimizer. This feature enables users to switch to low-bit optimizers seamlessly, further enhancing model training efficiency without significantly modifying their existing codebases.
Integrations and Future Developments
Torchao has been actively integrated into some of the most significant open-source projects in the machine-learning community. These integrations include serving as an inference backend for HuggingFace transformers, contributing to diffusers-torchao for accelerating diffusion models, and providing QLoRA and QAT recipes in torchtune. torchao’s 4-bit and 8-bit quantization techniques are also supported in the SGLang project, making it a valuable tool for those working on research and production deployments.
Moving forward, the PyTorch team has outlined several exciting developments for torchao. These include pushing the boundaries of quantization by going lower than 4-bit, developing performant kernels for high-throughput inference, expanding to more layers, scaling types, or granularities, and supporting additional hardware backends, such as MX hardware.
Key Takeaways from the Launch of torchao
Significant Performance Gains: Achieved up to 97% speedup for Llama 3 8B inference using advanced quantization techniques.
Reduction in Resource Consumption: Demonstrated 73% peak VRAM reduction for Llama 3.1 8B inference and 50% reduction in VRAM for diffusion models.
Versatile Quantization Support: Provides extensive options for quantization, including float8 and int4, with support for QAT to recover accuracy.
Low-Bit Optimizers: Introduced 8-bit and 4-bit optimizers as a drop-in replacement for AdamW.
Integration with Major Open-Source Projects: Actively integrated into HuggingFace transformers, diffusers-torchao, and other key projects.
In conclusion, the launch of torchao represents a major step forward for PyTorch, providing developers with a powerful toolkit to make models faster and more efficient across training and inference scenarios.
Check out the Details and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.











