
Google DeepMind Researchers Propose RT-Affordance: A Hierarchical Method that Uses Affordances as an Intermediate Representation for Policies
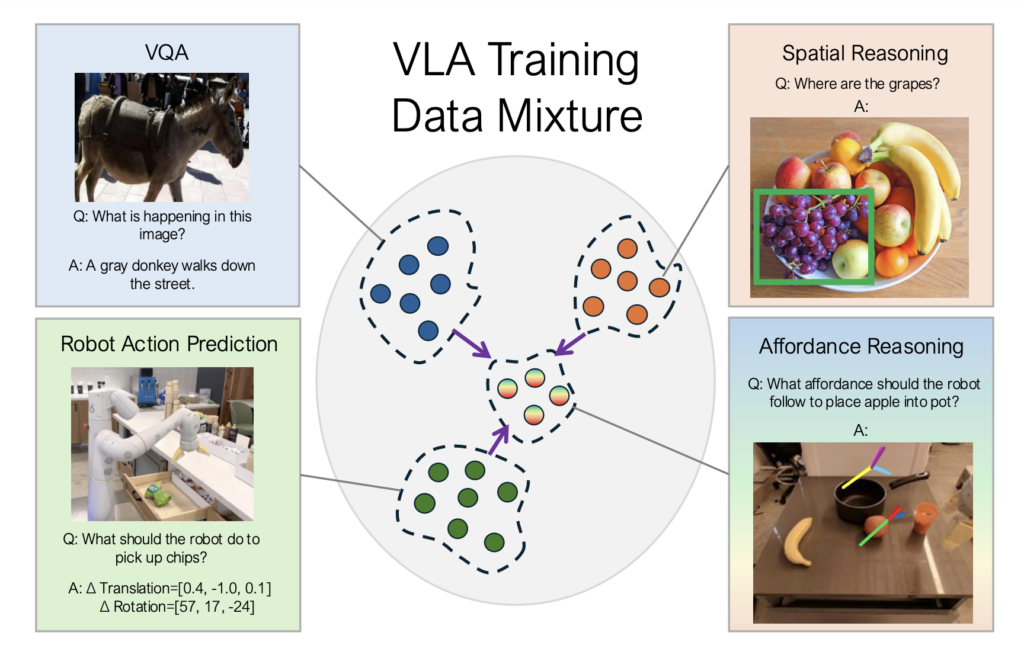
In recent years, there has been significant development in the field of large pre-trained models for learning robot policies. The term “policy representation” here refers to the different ways of interfacing with the decision-making mechanisms of robots, which can potentially facilitate generalization to new tasks and environments. Vision-language-action (VLA) models are pre-trained with large-scale robot data to integrate visual perception, language understanding, and action-based decision-making to guide robots in various tasks. On top of vision-language models (VLMs), they come up with the promise of generalization to new objects, scenes, and tasks. However, VLAs still need to be more reliable to be deployed outside the narrow lab settings they are trained in. While these drawbacks can be mitigated by expanding the scope and diversity of robot datasets, this is highly resource-intensive and challenging to scale. In simple words, these policy representations either need to provide more context or over-specified context that yields less robust policies.
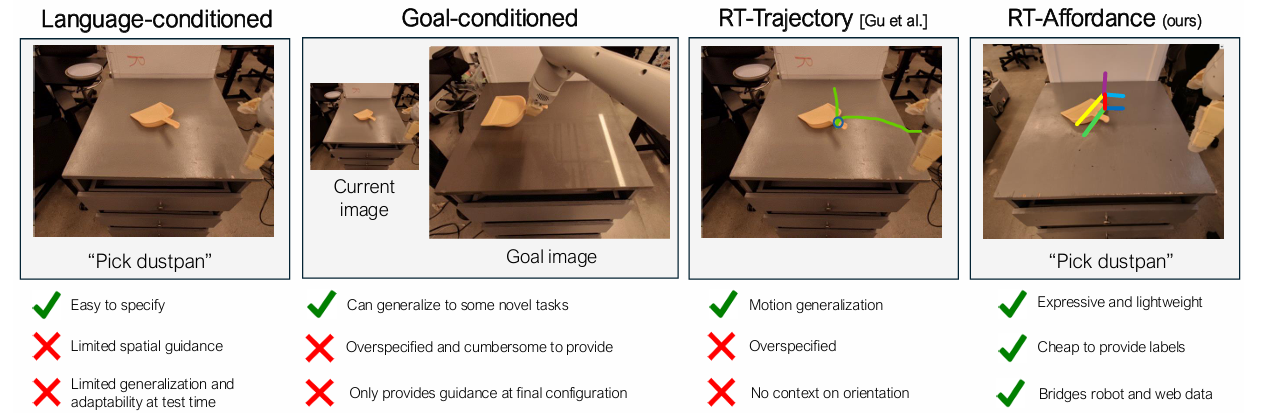
Existing policy representations such as language, goal images, and trajectory sketches are widely used and are helpful. One of the most common policy representations is conditioning on language. Most of the robot datasets are labeled with underspecified descriptions of the task, and language-based guidance does not provide enough guidance on how to perform the task. Goal image-conditioned policies provide detailed spatial information about the final goal configuration of the scene. However, goal images are high-dimensional, which presents learning challenges due to over-specification issues. Intermediate representation such as Trajectory sketches, or key points attempts to provide spatial plans for guiding the robot’s actions. While these spatial plans provide guidance, they still lack sufficient information for the policy on how to perform specific movements.

A team of researchers from Google DeepMind conducted detailed research on policy representation for robots and proposed RT-Affordance which is a hierarchical model that first creates an affordance plan given the task language, and then uses the policy on this affordance plan to guide the robot’s actions for manipulation. In robotics, affordance refers to the potential interactions that an object enables for a robot, based on its shape, size etc. The RT-Affordance model can easily connect heterogeneous sources of supervision including large web datasets and robot trajectories.
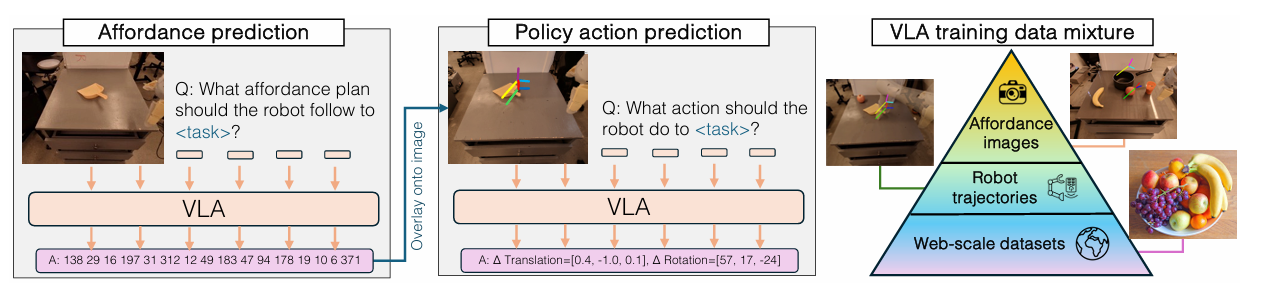
First, the affordance plan is predicted for the given task language and the initial image of the task. This affordance plan is then combined with language instructions to condition the policy for task execution. It is then projected onto the image, and following this, the policy is conditioned on images overlaid with the affordance plan. The model is co-trained on web datasets (the largest data source), robot trajectories, and a modest number of cheap-to-collect images labeled with affordances. This approach benefits from leveraging both robot trajectory data and extensive web datasets, allowing the model to generalize well across new objects, scenes, and tasks.

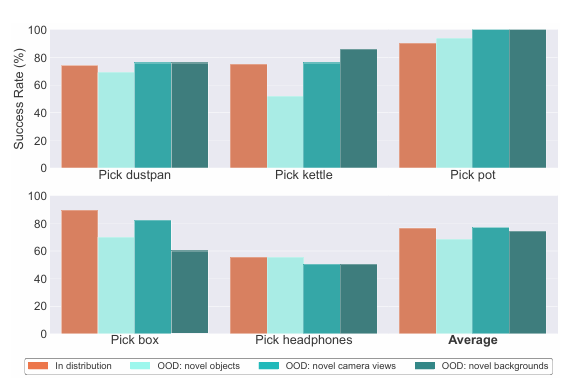
The research team conducted various experiments that mainly focused on how affordances help to improve robotic grasping, especially for movements of household items with complex shapes (like kettles, dustpans, and pots). A detailed evaluation showed that RT-A remains robust across various out-of-distribution (OOD) scenarios, such as novel objects, camera angles, and backgrounds. The RT-A model performed better than RT-2 and its goal-conditioned variant, achieving success rates of 68%-76% compared to RT-2’s 24%-28%. In tasks beyond grasping, like placing objects into containers, RT-A showed a significant performance with a 70% success rate. However, the performance of RT-A slightly dropped when it faced entirely new objects.
In conclusion, affordance-based policies are well-guided and also perform in a better way. The RT- Affordance method significantly improves the robustness and generalization of robot policies, which makes it a valuable tool for diverse manipulation tasks. Although it can not adapt to entirely new moments or skills, RT-Affordance surpasses traditional methods in terms of performance. This affordance technique opens the gate for various future research opportunities in robotics and can serve as a baseline for future studies!
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
Divyesh is a consulting intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of Technology, Kharagpur. He is a Data Science and Machine learning enthusiast who wants to integrate these leading technologies into the agricultural domain and solve challenges.










