
SmolLM2 Released: The New Series (0.1B, 0.3B, and 1.7B) of Small Language Models for On-Device Applications and Outperforms Meta Llama 3.2 1B
In recent years, the surge in large language models (LLMs) has significantly transformed how we approach natural language processing tasks. However, these advancements are not without their drawbacks. The widespread use of massive LLMs like GPT-4 and Meta’s LLaMA has revealed their limitations when it comes to resource efficiency. These models, despite their impressive capabilities, often demand substantial computational power and memory, making them unsuitable for many users, particularly those wanting to deploy models on devices like smartphones or edge devices with limited resources. Running these massive LLMs locally is an expensive task, both in terms of hardware requirements and energy consumption. This has created a clear gap in the market for smaller, more efficient models that can run on-device while still delivering robust performance.
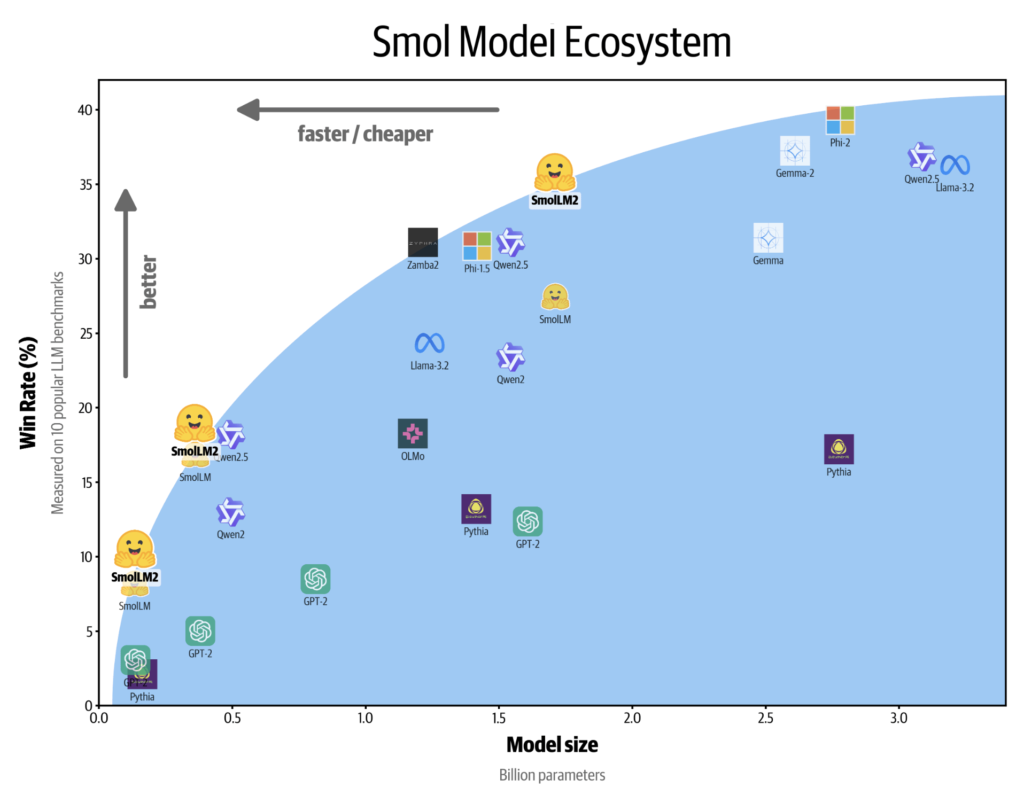
In response to this challenge, Hugging Face has released SmolLM2—a new series of small models specifically optimized for on-device applications. SmolLM2 builds on the success of its predecessor, SmolLM1, by offering enhanced capabilities while remaining lightweight. These models come in three configurations: 0.1B, 0.3B, and 1.7B parameters. Their primary advantage is the ability to operate directly on devices without relying on large-scale, cloud-based infrastructure, opening up opportunities for a variety of use cases where latency, privacy, and hardware limitations are significant factors. SmolLM2 models are available under the Apache 2.0 license, making them accessible to a broad audience of developers and researchers.
SmolLM2 is designed to overcome the limitations of large LLMs by being both compact and versatile. Trained on 11 trillion tokens from datasets such as FineWeb-Edu, DCLM, and the Stack, the SmolLM2 models cover a broad range of content, primarily focusing on English-language text. Each version is optimized for tasks such as text rewriting, summarization, and function calling, making them well-suited for a variety of applications—particularly for on-device environments where connectivity to cloud services may be limited. In terms of performance, SmolLM2 outperforms Meta Llama 3.2 1B, and in some benchmarks, such as Qwen2.5 1B, it has shown superior results.
The SmolLM2 family includes advanced post-training techniques, including Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO), which enhance the models’ capacity for handling complex instructions and providing more accurate responses. Additionally, their compatibility with frameworks like llama.cpp and Transformers.js means they can run efficiently on-device, either using local CPU processing or within a browser environment, without the need for specialized GPUs. This flexibility makes SmolLM2 ideal for edge AI applications, where low latency and data privacy are crucial.

The release of SmolLM2 marks an important step forward in making powerful LLMs accessible and practical for a wider range of devices. Unlike its predecessor, SmolLM1, which faced limitations in instruction following and mathematical reasoning, SmolLM2 shows significant improvements in these areas, especially in the 1.7B parameter version. This model not only excels in common NLP tasks but also supports more advanced functionalities like function calling—a feature that makes it particularly useful for automated coding assistants or personal AI applications that need to integrate seamlessly with existing software.
Benchmark results underscore the improvements made in SmolLM2. With a score of 56.7 on IFEval, 6.13 on MT Bench, 19.3 on MMLU-Pro, and 48.2 on GMS8k, SmolLM2 demonstrates competitive performance that often matches or surpasses the Meta Llama 3.2 1B model. Furthermore, its compact architecture allows it to run effectively in environments where larger models would be impractical. This makes SmolLM2 especially relevant for industries and applications where infrastructure costs are a concern or where the need for real-time, on-device processing takes precedence over centralized AI capabilities.
SmolLM2 offers high performance in a compact form suitable for on-device applications. With sizes from 135 million to 1.7 billion parameters, SmolLM2 provides versatility without compromising efficiency and speed for edge computing. It handles text rewriting, summarization, and complex function calls with improved mathematical reasoning, making it a cost-effective solution for on-device AI. As small language models grow in importance for privacy-conscious and latency-sensitive applications, SmolLM2 sets a new standard for on-device NLP.
Check out the Model Series here. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Model Depot: An Extensive Collection of Small Language Models (SLMs) for Intel PCs
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.










