
This AI Paper Introduces a Unified Perspective on the Relationship between Latent Space and Generative Models
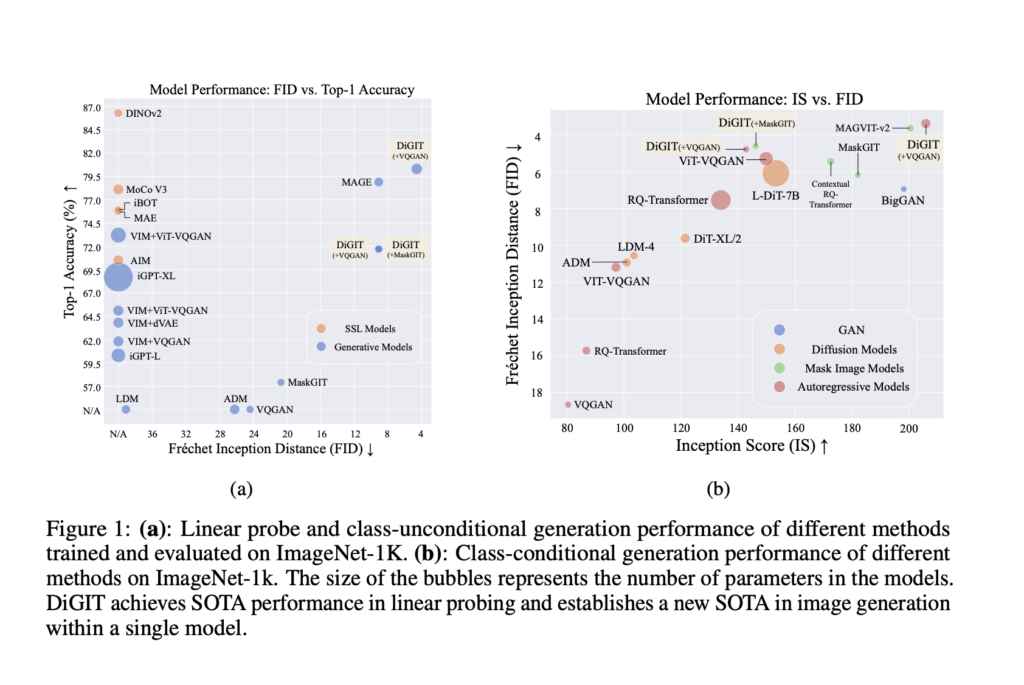
In recent years, there have been drastic changes in the field of image generation, mainly due to the development of latent-based generative models, such as Latent Diffusion Models (LDMs) and Mask Image Models (MIMs). Reconstructive autoencoders, like VQGAN and VAE, can reduce images into smaller and easier forms called low-dimensional latent space. This allows these models to create very realistic images. Considering the major influence of autoregressive (AR) generative models, such as Large Language Models in natural language processing (NLP), it’s interesting to explore whether similar approaches can work for images. Even though autoregressive models use the same latent space as models like LDMs and MIMs, they still somewhere fails in image generation. This stands in sharp contrast to natural language processing (NLP), where the autoregressive model GPT has achieved major dominance.
Current methods like LDMs and MIMs use reconstructive autoencoders, such as VQGAN and VAE, to transform images into a latent space. However, these approaches face challenges with stability and performance too. It is seen that, in the VQGAN model, as the image reconstruction quality improves (indicated by a lower FID score), the overall generation quality can actually decline. To address these issues, researchers have proposed a new method called Discriminative Generative Image Transformer (DiGIT). Unlike traditional autoencoder approaches, DiGIT separates the training of encoders and decoders, starting with the encoder-only training through a discriminative self-supervised model.
A team of researchers from the School of Data Science and the School of Computer Science and Technology at the University of Science and Technology of China, as well as the State Key Laboratory of Cognitive Intelligence and Zhejiang University propose Discriminative Generative Image Transformer (DiGIT). This method separates the training of encoders and decoders, beginning with encoder, training through a discriminative self-supervised model. This strategy enhances the stability of the latent space, making it more robust for autoregressive modeling. They utilize a method inspired by VQGAN to convert the encoder’s latent feature space into discrete tokens using K-means clustering. The research suggests that image autoregressive models can operate similarly to GPT models in natural language processing. The main contributions of this work include a unified perspective on the relationship between latent space and generative models, emphasizing the importance of stable latent spaces; a novel method that separates the training of encoders and decoders to stabilize the latent space; and an effective discrete image tokenizer that enhances the performance of image autoregressive models.
During testing, researchers matched each image patch with the nearest token from the codebook. After training a causal Transformer to predict the next token using these tokens, the researchers got good results on ImageNet. The DiGIT model surpasses previous techniques in image understanding and generation, demonstrating that using a smaller token grid can lead to higher accuracy. Experiments conducted by researchers highlighted the effectiveness of the proposed discriminative tokenizer, which significantly boosts model performance, as the number of parameters increases. The study also found that increasing the number of K-Means clusters enhances accuracy, reinforcing the advantages of a larger vocabulary in autoregressive modeling.

In conclusion, this paper presents a unified view of how latent space and generative models are related, highlighting the importance of a stable latent space in image generation and introducing a simple yet effective image tokenizer and an autoregressive generative model called DiGIT. The results also challenge the common belief that being good at reconstruction means also having an effective latent space for autoregressive generation. Through this work, the researchers aim to rekindle interest in the generative pre-training of image auto-regressive models, encourage a reevaluation of the fundamental components that define latent space for generative models, and make this a step towards new technologies and methods!
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Divyesh is a consulting intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of Technology, Kharagpur. He is a Data Science and Machine learning enthusiast who wants to integrate these leading technologies into the agricultural domain and solve challenges.










