
Meissonic: A Non-Autoregressive Mask Image Modeling Text-to-Image Synthesis Model that can Generate High-Resolution Images
Large Language Models (LLMs) have demonstrated remarkable progress in natural language processing tasks, inspiring researchers to explore similar approaches for text-to-image synthesis. At the same time, diffusion models have become the dominant approach in visual generation. However, the operational differences between the two approaches present a significant challenge in developing a unified methodology for language and vision tasks. Recent developments like LlamaGen have ventured into autoregressive image generation using discrete image tokens; however, it is inefficient due to the large number of image tokens compared to text tokens. Non-autoregressive methods like MaskGIT and MUSE have emerged, cutting down on the number of decoding steps, but failing to produce high-quality, high-resolution images.
Existing attempts to solve the challenges in text-to-image synthesis have mainly focused on two approaches: diffusion-based and token-based image generation. Diffusion models, like Stable Diffusion and SDXL, have made significant progress by working within compressed latent spaces and introducing techniques like micro-conditions and multi-aspect training. The integration of transformer architectures, as seen in DiT and U-ViT, has further enhanced the potential of diffusion models. However, these models still face challenges in real-time applications and quantization. Token-based approaches like MaskGIT and MUSE, have introduced masked image modeling (MIM) to overcome the computational demands of autoregressive methods.
Researchers from Alibaba Group, Skywork AI, HKUST(GZ), HKUST, Zhejiang University, and UC Berkeley have proposed Meissonic, an innovative method to elevate non-autoregressive MIM text-to-image synthesis to a level comparable with state-of-the-art diffusion models like SDXL. Meissonic utilizes a comprehensive suite of architectural innovations, advanced positional encoding strategies, and optimized sampling conditions to enhance MIM’s performance and efficiency. The model uses high-quality training data, micro-conditions informed by human preference scores, and feature compression layers to improve image fidelity and resolution. The Meissonic can produce 1024 × 1024 resolution images and often outperforms existing models in generating high-quality, high-resolution images.
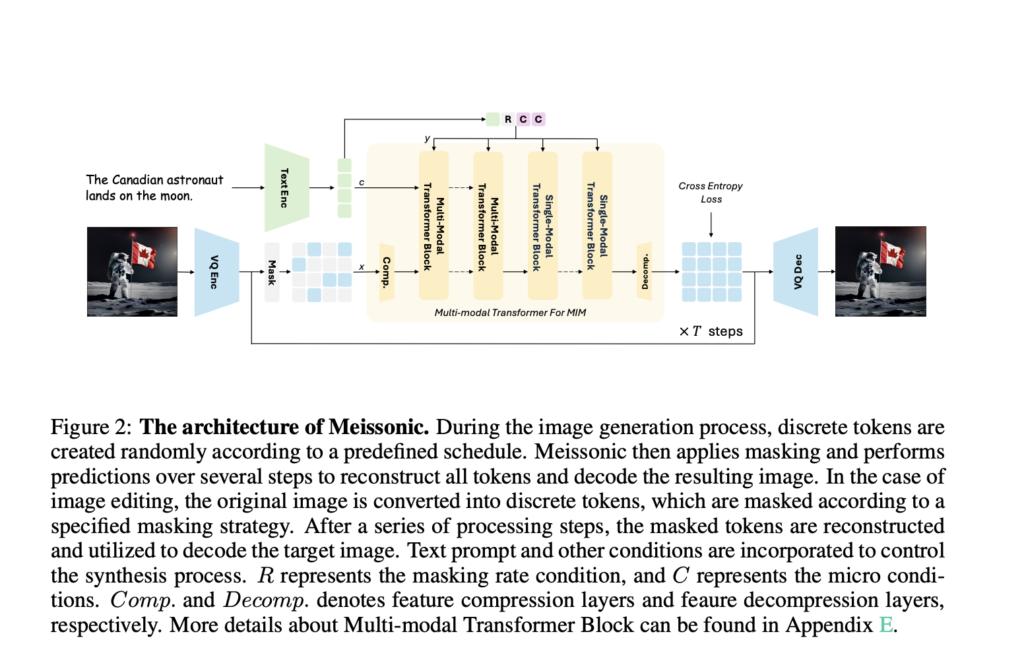
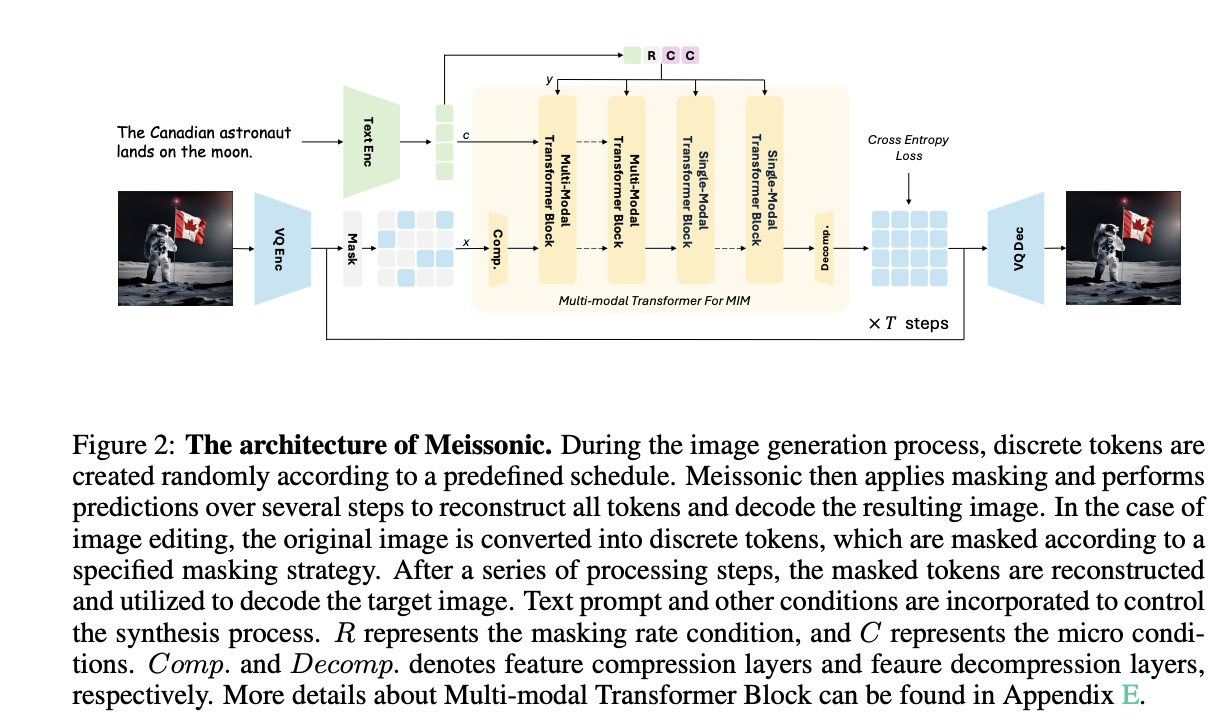
Meissonic’s architecture integrates a CLIP text encoder, a vector-quantized (VQ) image encoder and decoder, and a multi-modal Transformer backbone for efficient high-performance text-to-image synthesis:

The VQ-VAE model converts raw image pixels into discrete semantic tokens using a learned codebook.
A fine-tuned CLIP text encoder with a 1024 latent dimension is used for optimal performance.
The multi-modal Transformer backbone utilizes sampling parameters and Rotary Position Embeddings for spatial information encoding.
Feature compression layers are used to handle high-resolution generation efficiently.
The architecture also includes QK-Norm layers and implements gradient clipping to enhance training stability and reduce NaN Loss issues during distributed training.
Meissonic, optimized to 1 billion parameters, runs efficiently on 8GB VRAM, making inference and fine-tuning convenient. Qualitative comparisons show Meissonic’s image quality and text-image alignment capabilities. Human evaluations using K-Sort Arena and GPT-4 assessments indicate that Meissonic achieves performance comparable to DALL-E 2 and SDXL in human preference and text alignment, with improved efficiency. Meissonic is benchmarked against state-of-the-art models using the EMU-Edit dataset in image editing tasks, covering seven different operations. The model demonstrated versatility in both mask-guided and mask-free editing, achieving great performance without specific training on image editing data or instruction datasets.
In conclusion, researchers introduced Meissonic, an approach to elevate non-autoregressive MIM text-to-image synthesis. The model incorporates innovative elements such as a blended transformer architecture, advanced positional encoding, and adaptive masking rates to achieve superior performance in high-resolution image generation. Despite its compact 1B parameter size, Meissonic outperforms larger diffusion models while remaining accessible on consumer-grade GPUs. Moreover, Meissonic aligns with the emerging trend of offline text-to-image applications on mobile devices, exemplified by recent innovations from Google and Apple. It enhances the user experience and privacy in mobile imaging technology, empowering users with creative tools while ensuring data security.
Check out the Paper and Model. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.










