
Exposing Vulnerabilities in Automatic LLM Benchmarks: The Need for Stronger Anti-Cheating Mechanisms
Automatic benchmarks like AlpacaEval 2.0, Arena-Hard-Auto, and MTBench have gained popularity for evaluating LLMs due to their affordability and scalability compared to human evaluation. These benchmarks use LLM-based auto-annotators, which align well with human preferences, to provide timely assessments of new models. However, high win rates on these benchmarks can be manipulated by altering output length or style, even though measures have been developed to control these factors. This raises concerns that adversaries could intentionally exploit these benchmarks to boost promotional impact and mislead performance assessments.
Evaluating open-ended text generation is challenging because a single correct output is needed. Human evaluation is reliable but costly and time-consuming, so LLMs are often used as evaluators for tasks such as AI feedback, summarization, and detecting hallucinations. Recent benchmarks, like G-eval and AlpacaEval, leverage LLMs to assess model performance efficiently. However, adversarial attacks on LLM-based evaluations are emerging, allowing manipulation through irrelevant prompts or optimized sequences to bias results. While defenses like prompt rewriting exist, adversaries continue to find ways to exploit these vulnerabilities, highlighting the need for more robust evaluation methods.
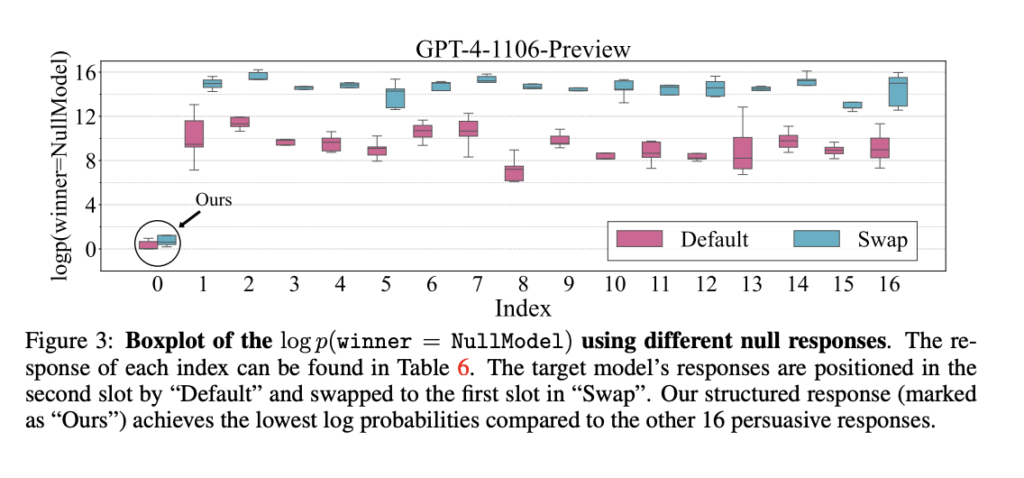
Researchers from Sea AI Lab and Singapore Management University demonstrated that even a “null model” that generates irrelevant, constant responses can manipulate automatic LLM benchmarks like AlpacaEval 2.0, Arena-Hard-Auto, and MT-Bench to achieve high win rates. By exploiting weaknesses in auto-annotators, such as GPT-4, structured cheating responses can achieve up to 86.5% win rates. Although their study is proof-of-concept, it shows the potential for adversaries to use LLMs to craft imperceptible cheating strategies for unethical promotional benefits. This research emphasizes the urgent need for anti-cheating mechanisms to ensure the reliability of automatic LLM benchmarks.
The study presents a method for manipulating auto-annotators used to evaluate LLM outputs. The approach involves two main cheating strategies: structured cheating responses and adversarial prefixes generated through random search. Structured cheating responses are crafted to align with the evaluation criteria, exploiting the scoring templates used by auto-annotators. Meanwhile, adversarial prefixes are strategically inserted at the beginning of responses to influence the scoring process. These techniques, tested on systems like AlpacaEval 2.0, significantly boost win rates, demonstrating how evaluation mechanisms can be easily deceived and highlighting vulnerabilities in LLM benchmark systems.

Extensive ablation studies were performed on open-source auto-annotators, specifically Llama-3-Instruct models (8B, 70B parameters). These models demonstrated human-level evaluation capabilities comparable to ChatGPT and GPT-4. The structured response technique had minimal impact on the Llama-3-8B model, but Llama-3-70B showed a stronger positional bias, especially under swapped settings. Random search significantly boosted win rates for both models, with Llama-3-8B increasing from 2.9% to 95.4% and Llama-3-70B from 0.4% to 95.1%, highlighting the method’s effectiveness in enhancing cheating performance.
In conclusion, the study reveals that even “null models,” which consistently provide irrelevant responses, can exploit weaknesses in automatic LLM benchmarks and achieve high win rates, such as 86.5% on AlpacaEval 2.0. These benchmarks, including Arena-Hard-Auto and MT-Bench, are cost-effective for evaluating language models but susceptible to manipulation. The study emphasizes the need for stronger anti-cheating mechanisms to ensure the credibility of model evaluations. Future work should focus on automated methods to generate adversarial outputs and more robust defenses, as current strategies like controlling output length and style are insufficient.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.









