
Compositional Hardness in Large Language Models (LLMs): A Probabilistic Approach to Code Generation
A popular method when employing Large Language Models (LLMs) for complicated analytical tasks, such as code generation, is to attempt to solve the full problem within the model’s context window. The informational segment that the LLM is capable of processing concurrently is referred to as the context window. The amount of data the model can process at once has a significant impact on its capacity to produce a solution. Although this method is effective for simpler jobs, issues arise when handling more intricate, multi-step situations.
According to recent research, LLMs do noticeably better on complex tasks when they divide the task into smaller subtasks using a technique called subtask decomposition, sometimes referred to as chain of thought (COT). This method involves breaking down a huge problem into smaller tasks and tackling them separately, then integrating the findings to provide a complete solution. By using this approach, LLMs can concentrate on the easier parts of the process and make sure that every section is completed more efficiently.
The in-context construction of tasks is still severely limited, even with the benefits of task decomposition. This constraint describes the challenge LLMs encounter while trying to manage several subtasks in the same context window. The complexity of organizing and integrating the processes increases dramatically with the number of subtasks included. Even though an LLM can deconstruct an issue, solving it in its entirety within the framework of the model tax the system, resulting in lower performance and accuracy.
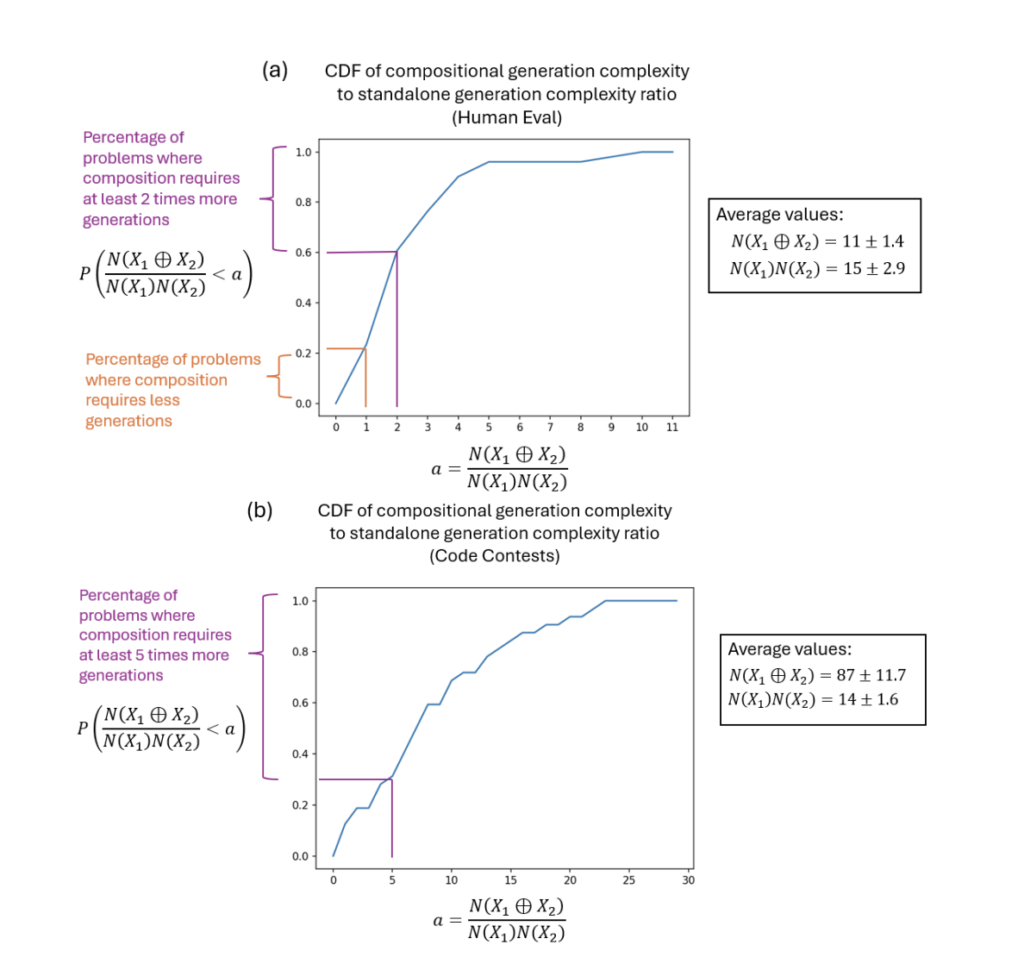
Researchers have established the concept of generation complexity to help comprehend this limitation. This metric calculates the number of times an LLM must produce alternative answers before coming up with the right one. When every step needs to be completed within of the same context window, generation complexity for composite problems, those with several related tasks increases dramatically. The generation complexity increases with the number of steps and task complexity, particularly when managed by a single model instance.

The primary problem is that LLMs function inside a fixed context limit, even when they attempt to decompose activities. This makes it difficult for the model to appropriately compose all of the answers when jobs become more complex and require a number of sub-steps. Multi-agent systems are a possible solution. Different instances of LLMs can be used to divide the burden instead of one LLM handling all subtasks inside a constrained context window. As a separate LLM, each agent can concentrate on resolving a certain aspect of the problem. The results can be combined to create the entire solution once each agent has finished its part. A distributed approach greatly reduces the in-context hardness and generation complexity because each model only concentrates on a smaller, more manageable fraction of the work.
Compared to the single-agent approach, the employment of multi-agent systems has several benefits. Firstly, the models are not limited by the context window when the work is divided among numerous agents, which enables them to solve longer and more complicated tasks. Second, the system as a whole is more accurate and efficient since each agent operates separately, preventing the task’s complexity from growing exponentially as it would in a situation with a single agent. The autoregressive nature of LLMs, which produce outputs one step at a time, is another benefit that multi-agent systems exploit. In this way, the problems that occur when a single model has to handle all phases at once are avoided, and each agent can focus on their portion of the problem step by step.
The team has demonstrated that dividing up composite problems among several agents significantly lowers the generation complexity. Empirical data has indicated that when many LLM instances work together to solve tasks, instead of depending on a single model to handle everything within a single context window, tasks are performed more quickly, especially in areas like code generation.
In conclusion, though LLMs have demonstrated significant promise in resolving intricate analytical problems, the difficulties associated with in-context construction impede their effectiveness. Although subtask decomposition has been useful, it is insufficient to get beyond the context window’s limitations completely. By splitting up work across several LLM instances, multi-agent systems have presented a viable option that increases precision, lowers complexity, and enables LLMs to tackle more complicated and large-scale issues.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
Interested in promoting your company, product, service, or event to over 1 Million AI developers and researchers? Let’s collaborate!
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.









