
Mirage: A Multi-Level Tensor Algebra Super-Optimizer that Automates GPU Kernel Generation for PyTorch Applications
With the increasing growth of artificial intelligence—introduction of large language models (LLMs) and generative AI—there has been a growing demand for more efficient graphics processing units (GPUs). GPUs are specialized hardware extensively used for high computing tasks and capable of executing computations in parallel. Writing proper GPU kernels is important to utilize GPUs to their full potential. This task is quite time-consuming and complex, requiring deep expertise in GPU architecture and some programming languages like C++, CUDA, etc.
Machine Learning ML compilers like TVM, Triton, and Mojo provide certain automation but still need manual handling of the GPU kernels to obtain the optimal result. To achieve optimal results and avoid manual tasking, researchers at Carnegie Mellon University have developed Mirage, an innovative tool designed to automate the generation of high-performance GPU kernels by searching for and generating them. The kernels generated by Mirage can directly be used on PyTorch tensors and be called in PyTorch programs. Users need to write a few lines of code in Mirage compared to the traditional script, which uses many lines.
Mirage can be seen as a future changer, attaining high productivity, better performance, and stronger correctness in AI applications. Writing manual codes requires substantial engineering expertise due to the complex nature of GPU architecture, but Mirage simplifies the process by automatically generating kernels, easing and simplifying the tasks for engineers.
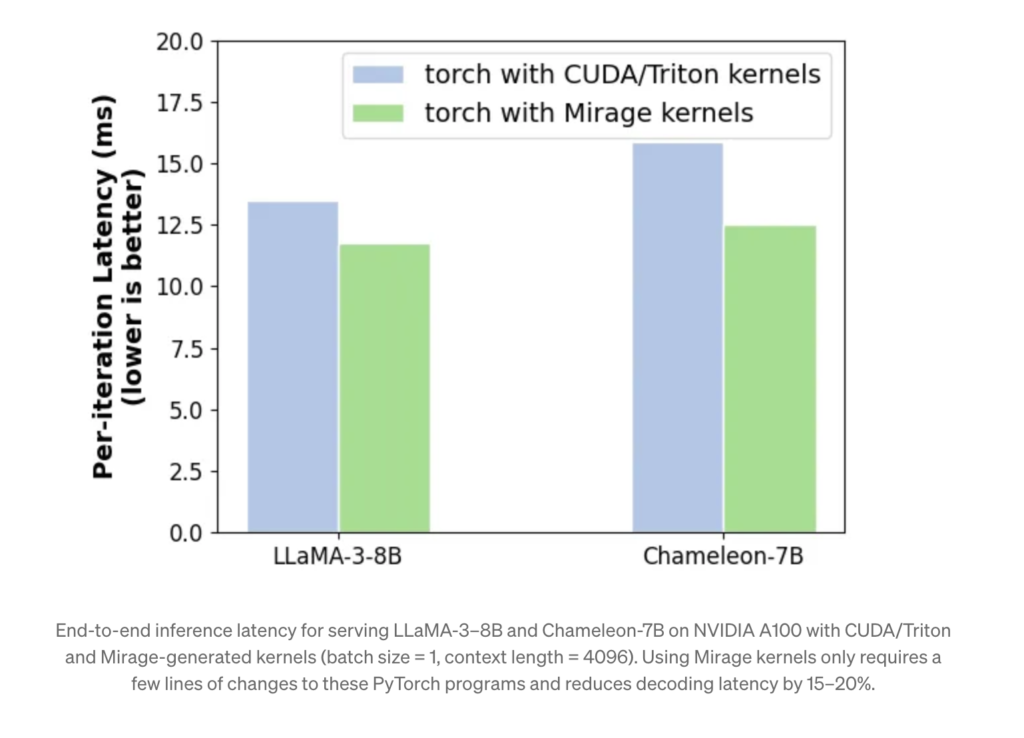
Manually written GPU kernels might have some errors, which makes it hard to achieve the required results, but research on Mirage has shown that kernels generated by Mirage are 1.2x-2.5x times faster than the best human-written code. Also, integrating Mirage into PyTorch reduces overall latency by 15-20%.

# Use Mirage to generate GPU kernels for attention
import mirage as mi
graph = mi.new_kernel_graph()
Q = graph.new_input(dims=(64, 1, 128), dtype=mi.float16)
K = graph.new_input(dims=(64, 128, 4096), dtype=mi.float16)
V = graph.new_input(dims=(64, 4096, 128), dtype=mi.float16)
A = graph.matmul(Q, K)
S = graph.softmax(A)
O = graph.matmul(S, V)
optimized_graph = graph.superoptimize()
Code in Mirage takes few lines compared to traditional method with many lines
All the computations in GPUs are centered around kernels, which are functions running parallely around multiple streaming multiprocessors (SM) in a single-program-multiple data fashion (SPMD). Kernels organize computation in a grid of thread blocks, with each thread block running on a single SM. Each block further has multiple threads to perform calculations on individual data elements.
GPU follows a particular memory hierarchy with:
Register file for quick data access
Shared Memory: Shared by all threads in a block for efficient data exchange.
Device Memory: Accessible by all threads in a kernel
The architecture is represented with the help of the uGraph representation, which contains graphs on multiple levels: Kernel level, thread block level and thread level with kernel-level encapsulating computation over the entire GPU, thread block level addressing computation on an individual streaming multiprocessor (SM), and thread graph addressing computation at the CUDA or tensor core level. The uGraph provides a structured way to represent GPU computations.
Four Categories of GPU Optimization:
1. Normalization + Linear
LLMs generally use LayernNorm, RMSNorm, GroupNorm, and BatchNorm techniques, which are often treated separately by ML compilers. This separation is because normalization techniques require both reduction and broadcast operations. These normalization layers can be fused with linear ones by matrix multiplication.
2. LoRA + Linear
It fuses low-rank adaptation (LoRA), a technique to adapt pre-trained models to new tasks or datasets while reducing computational requirements with linear layers. It is 1.6x faster than the existing systems.
3. Gated MLP
It combines two MatMuls, SiLU activation, and element-wise multiplication. Gated MLP reduces kernel launch overhead and device memory access to 1.3x faster than the best baseline.
4. Attention variants
a. Query-Key Normalization
Chameleon, ViT-22B, and Google’s recent paper have introduced query-key normalization and fused LayerNorm into the attention kernel. This custom kernel also performs existing GPU optimizations tailored for attention with a 1.7x-2.5x performance improvement.
b. Multi-Head Latent Attention
It optimizes memory usage by compressing traditional key-value cache of attention into a more compact latent vector. This change introduces two linear layers before attention. Mirage generates a custom kernel that integrates the linear layers with the attention mechanism into a single kernel. This prevents storing intermediate key-value vectors in the GPU device memory.
In conclusion, Mirage addresses the critical challenge of dealing with high GPU kernels in advanced artificial intelligence problems. It eliminates the problems of significant time investment, high coding expertise, and error generation by providing the best optimal GPU kernels that work in a PyTorch-based environment. It also deals with the loopholes that manual computing might miss, accelerating the deployment of LLMs and other AI technologies across real-world applications.
Check out the GitHub page and Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Interested in promoting your company, product, service, or event to over 1 Million AI developers and researchers? Let’s collaborate!
Nazmi Syed is a consulting intern at MarktechPost and is pursuing a Bachelor of Science degree at the Indian Institute of Technology (IIT) Kharagpur. She has a deep passion for Data Science and actively explores the wide-ranging applications of artificial intelligence across various industries. Fascinated by technological advancements, Nazmi is committed to understanding and implementing cutting-edge innovations in real-world contexts.









